
논문을 읽다 보면 보이는 통계 수치들이 있습니다. 각종 알파벳으로 이뤄진 암호 같은 통계 수치들... 한번 살펴보도록 하겠습니다.
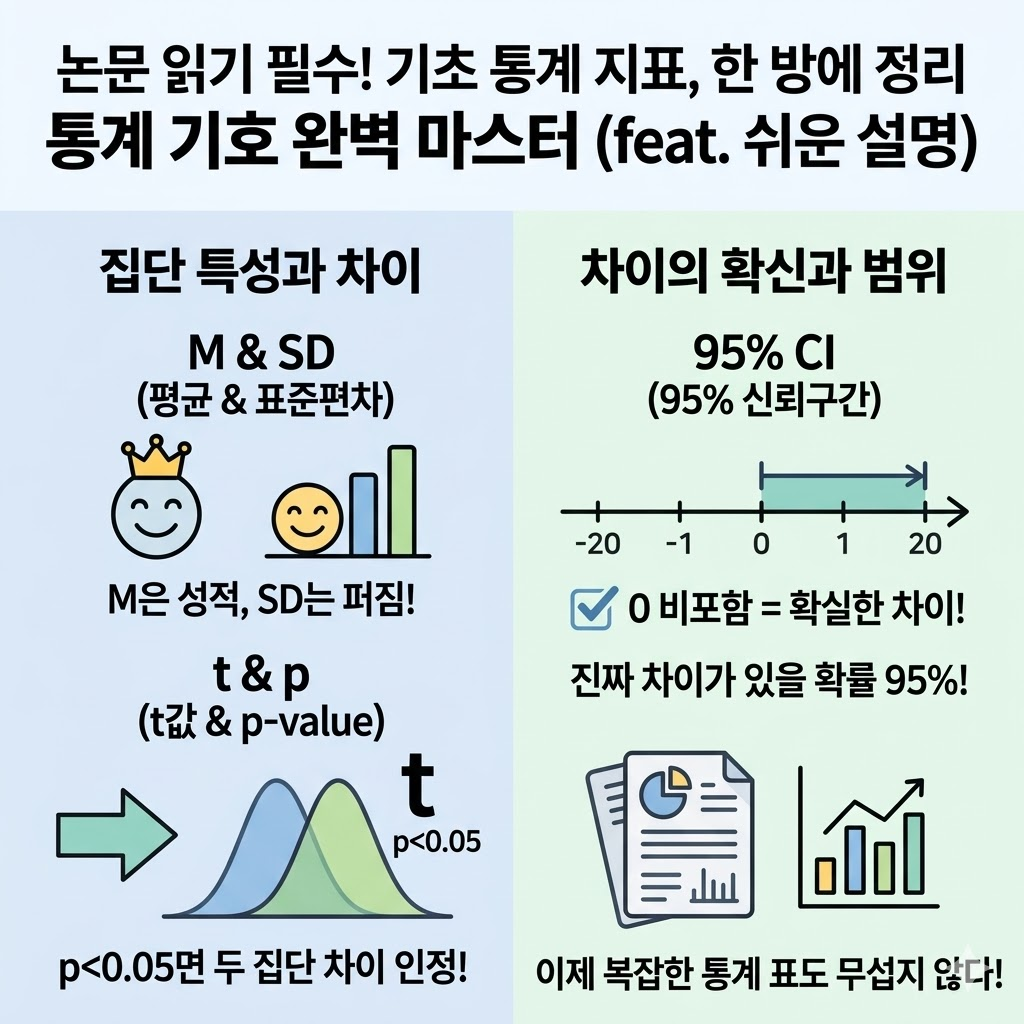
1. 집단의 점수 분포 확인하기 (M, SD)
먼저 집단이 전반적으로 어떤 상태인지 확인하는 기본 지표입니다.
📊 데이터 예시:
- • 실험군(AI를 통해 학습한 그룹): M = 5.85, SD = 0.35
- • 대조군(교사와 함께 학습한 그룹): M = 5.54, SD = 0.62
가. M (Mean): 집단의 평균 점수
- 실험군의 평균(5.85)이 대조군(5.54)보다 높습니다.
- "일단 AI로 공부한 그룹의 전반적인 성적이 더 좋구나"라고 1차적인 판단을 내릴 수 있습니다.
나. SD (Standard Deviation): 표준편차 (집단의 고른 정도)
- 실험군의 SD(0.35)가 대조군(0.62)보다 훨씬 작습니다.
- 이는 AI 학습 그룹 학생들의 실력이 서로 비슷하게(고르게) 분포되어 있고, 대조군은 실력 차이가 꽤 크다는 것을 의미합니다.
2. 차이가 '진짜'인지 밝히는 지표 (t, df, p)
평균이 높은 것이 단지 '운'이었을까요, 아니면 '진짜 효과'였을까요?
📊 데이터 예시 (사후 테스트):
t(45) = -2.08, p = 0.04
가. t (t-value): 차이의 선명도
- 두 집단의 평균 차이가 집단 내 변동성(잡음)을 뚫고 나올 만큼 선명한지 보여줍니다.
- 절댓값이 2를 넘었으므로(2.08), 차이가 꽤 선명하다고 볼 수 있습니다.
💡 왜 절댓값이 2를 넘으면 유의미한가요?
1) 통계학의 95% 법칙: 학자들은 어떤 현상이 "단순 우연이 아닐 확률이 95% 이상"일 때 가치를 인정합니다.
2) 임계치 1.96: t-분포 그래프에서 양 끝 5%(우연) 영역으로 벗어나는 지점이 보통 1.96입니다.
3) 반올림의 미학: 실무적으로는 1.96 대신 기억하기 쉬운 2를 기준으로 삼습니다. 그래서 t가 2를 넘으면 "잡음을 뚫고 나온 선명한 신호"라고 봅니다.
나. df (Degrees of Freedom): 데이터의 양
- 독립표본 t-검정에서 df = 45라면 전체 연구 대상자가 약 47명 수준임을 알려줍니다. 표본이 적절하여 분석 결과에 신뢰를 가질 수 있습니다.
💡 왜 df=45인데 인원이 47명인가요?
두 집단을 비교할 때는 자유도(df) = 전체 인원(N) - 2 공식을 씁니다.
두 집단의 평균값을 계산하는 과정에서 각 집단당 1개씩, 총 2개의 데이터가 자유를 잃고 고정되기 때문에 전체 인원에서 2를 빼주는 것입니다.
다. p (Probability): 우연일 확률
- 위 연구에서 p = 0.04가 나왔습니다. 이는 "실제 효과가 없는데 우연히 이런 차이가 날 확률이 4%뿐"이라는 뜻입니다.
- 기준인 0.05보다 작으므로 "AI 학습 효과가 진짜였다"고 확신하며 결론을 내립니다.
3. 신뢰구간 (95% CI)
📊 데이터 예시:
95% CI [-0.60, -0.01]
- 진짜 평균 차이가 존재할 것으로 95% 확신하는 범위입니다.
- 구간 안에 0(차이가 없음)이 포함되지 않으므로, 두 집단 사이에 확실한 차이가 있음을 다시 한번 증명합니다.
💡 신뢰구간에서 '0'이 포함 안 된다는 건?
우리는 지금 '차이'를 계산하고 있습니다. 만약 차이가 없다면 값은 0이 되어야 합니다. (5-5=0 인 것처럼요)
신뢰구간이 [-0.60, -0.01]처럼 모두 음수이거나 모두 양수여서 0이 포함되지 않는다면, 아무리 보수적으로 잡아도 차이가 0(없음)은 절대 아니다라고 확신할 수 있는 상태입니다.
반면 0이 포함되면 "사실 차이가 0일 수도 있겠는데?"라는 의심을 지울 수 없어 통계적으로 유의미하지 않다고 봅니다.

